Paper abstract and model overview
This section now introduces the paper itself before the listening cases, using the actual abstract, the final module framework figure, and the data construction and evaluation pipeline figure from the paper.
CapTalk paper abstract
Voice design from natural language descriptions is emerging as a new task in text-to-speech multimodal generation, aiming to synthesize speech with target timbre and speaking style without relying on reference audio. However, existing methods mainly focus on single-utterance generation, leaving conversational voice design largely unexplored.
In this work, we extend voice design to dialogue, enabling better target speaker modeling and turn-level expressive control in natural conversational settings. We propose CapTalk, a unified caption-conditioned text-audio autoregressive framework for both single-utterance and dialogue voice design. CapTalk uses utterance-level captions for single-utterance voice design and speaker-level captions for dialogue speaker modeling, and further introduces a CoT control sequence in dialogue to explicitly plan turn-level dynamic attributes.
To resolve the conflict between stable timbre preservation and context-adaptive expression, we propose a hierarchical variational conditioning module with an utterance-level speaker encoder to better balance stable timbre preservation and context-adaptive expression. This enables timbre reuse while keeping expression adaptive to the current utterance and, in dialogue, the surrounding context. We also build a comprehensive evaluation protocol for both single-utterance and dialogue settings.
Experiments show that CapTalk achieves state-of-the-art performance on a single-utterance voice design benchmark and delivers better expression controllability and contextual appropriateness in multi-turn dialogue.
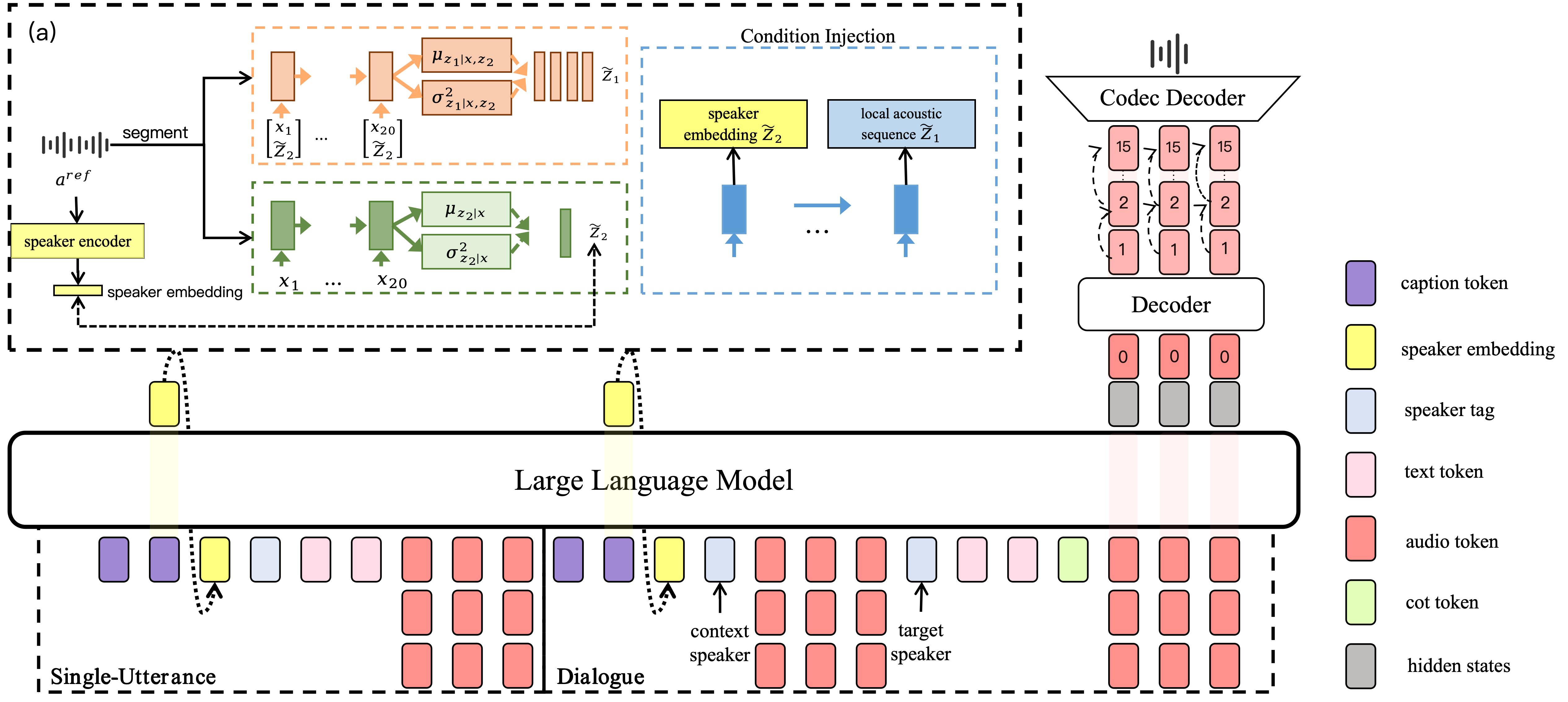
CapTalk module framework
The figure below is the framework image from the paper. It shows the hierarchical variational timbre conditioning module and the unified caption-conditioned autoregressive generation pipeline for both single-utterance and dialogue settings.
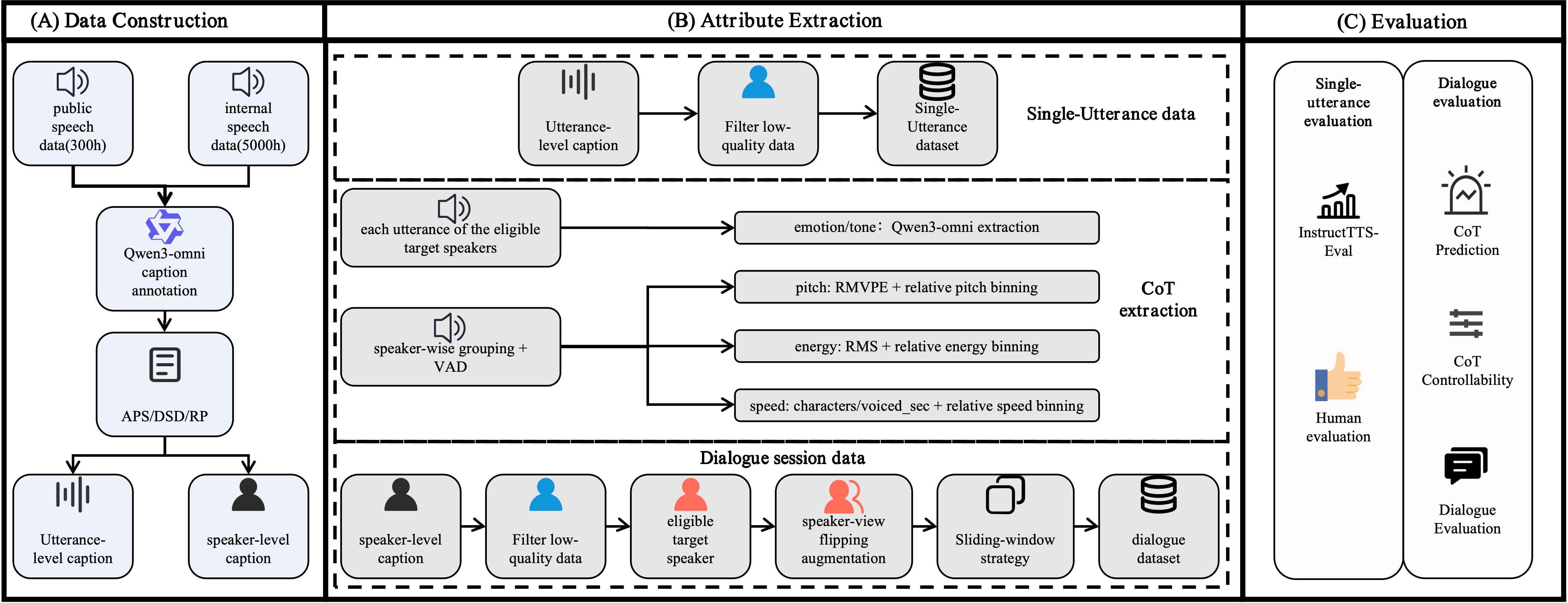
Data construction, attribute extraction, and evaluation
Figure 2 is worth keeping on the demo page because it clarifies where the single-utterance and dialogue data come from, how CoT attributes are extracted, and how the evaluation protocol is organized.
Single-Utterance Voice Design
The single-utterance section serves two purposes: it matches the benchmark narrative in Table 1 and highlights why CapTalk is more balanced across caption styles, especially on RP.
Prompt compatibility note: CapTalk, Qwen3-TTS, Ming-omni-tts, and VoiceSculptor accept the original free-form caption directly. Fish Speech S2 Pro does not natively follow long natural-language speaker descriptions, so we convert the same caption semantics into short bracketed control tags following its official prompt interface. The Fish results should therefore be read as an interface-adapted comparison with matched caption meaning, rather than an identical raw prompt string match.
Table 1. Results on the InstructTTSEval-ZH Benchmark
| Model | APS | DSD | RP | AVG |
|---|---|---|---|---|
| Qwen3TTS-12Hz-1.7B-VD | 87.10 | 76.00 | 55.20 | 72.77 |
| Ming-omni-tts-0.5B | 84.90 | 72.20 | 53.90 | 70.33 |
| VoiceSculptor | 73.77 | 65.40 | 47.60 | 62.26 |
| Fish Speech S2 Pro | 29.61 | 50.80 | 42.60 | 41.00 |
| CapTalk-1.5B (Ours) | 84.10 | 75.40 | 61.70 | 73.73 |
Table 2. Human evaluation for single-utterance voice design
All metrics rated on a 1–5 scale. MOS denotes human-rated naturalness.
| Model | Overall | Identity | Timbre | Express. | Role | Stabil. | MOS |
|---|---|---|---|---|---|---|---|
| Ming-omni-tts-0.5B | 3.95 | 4.22 | 4.03 | 4.06 | 3.88 | 4.27 | 3.91 |
| Qwen3TTS-12Hz-1.7B-VD | 4.20 | 3.78 | 4.15 | 4.12 | 3.85 | 4.35 | 3.82 |
| VoiceSculptor | 3.00 | 3.15 | 2.89 | 2.74 | 2.81 | 3.25 | 2.87 |
| Fish Speech S2 Pro | 2.07 | 2.19 | 2.02 | 1.82 | 1.86 | 2.29 | 2.11 |
| CapTalk (Ours) | 4.24 | 3.98 | 3.59 | 4.10 | 4.17 | 4.38 | 4.20 |
APS caption comparison
Structured promptAPS uses structured acoustic attributes. This card shows two examples under the same prompt style.
Example A
| Model | Audio |
|---|---|
| CapTalk (Ours) | |
| Qwen3TTS-12Hz-1.7B-VD | |
| Ming-omni-tts-0.5B | |
| VoiceSculptor | |
| Fish Speech S2 Pro |
Example B
| Model | Audio |
|---|---|
| CapTalk (Ours) | |
| Qwen3TTS-12Hz-1.7B-VD | |
| Ming-omni-tts-0.5B | |
| VoiceSculptor | |
| Fish Speech S2 Pro |
DSD caption comparison
Speaker descriptionDSD uses free-form speaker description prompts. This card shows two examples under the same prompt style.
Example A
| Model | Audio |
|---|---|
| CapTalk (Ours) | |
| Qwen3TTS-12Hz-1.7B-VD | |
| Ming-omni-tts-0.5B | |
| VoiceSculptor | |
| Fish Speech S2 Pro |
Example B
| Model | Audio |
|---|---|
| CapTalk (Ours) | |
| Qwen3TTS-12Hz-1.7B-VD | |
| Ming-omni-tts-0.5B | |
| VoiceSculptor | |
| Fish Speech S2 Pro |
RP caption comparison
Role promptRP is role- and intent-heavy. This card shows two examples under the same prompt style.
Example A
| Model | Audio |
|---|---|
| CapTalk (Ours) | |
| Qwen3TTS-12Hz-1.7B-VD | |
| Ming-omni-tts-0.5B | |
| VoiceSculptor | |
| Fish Speech S2 Pro |
Example B
| Model | Audio |
|---|---|
| CapTalk (Ours) | |
| Qwen3TTS-12Hz-1.7B-VD | |
| Ming-omni-tts-0.5B | |
| VoiceSculptor | |
| Fish Speech S2 Pro |
Single-Utterance Scaling Study
Within Section 1This subsection stays under single-utterance voice design. Each prompt keeps the caption style and target text fixed, and only changes the training scale: 300h, 1500h, 3000h, 5000h, and 5000h+300h. The 300h is public acted-style data; 1500h / 3000h / 5000h are internal single-utterance speech in a natural casual-talk style. As reported in the paper, this casual-style data provides broader coverage while acted speech contributes stronger expressive attributes, and the mixed 5000h+300h setup yields the best overall result (AVG 73.73).
| Data Scale | Type | APS | DSD | RP | AVG |
|---|---|---|---|---|---|
| 300h | Acted | 82.78 | 71.41 | 49.10 | 67.76 |
| 1500h | Conversat. | 70.20 | 57.80 | 41.20 | 56.40 |
| 3000h | Conversat. | 74.00 | 62.40 | 46.80 | 61.07 |
| 5000h | Conversat. | 79.10 | 68.30 | 55.10 | 67.50 |
| 5000h+300h | Conversat.+Acted | 84.10 | 75.40 | 61.70 | 73.73 |
Table 5. Scaling law results for single-utterance voice design on InstructTTSEval-ZH.
APS scaling ladder
Structured promptTwo APS examples are shown below to illustrate how stronger data scale improves prompt-following while keeping the voice natural.
Example A
| Scale | Audio |
|---|---|
| 300h | |
| 1500h | |
| 3000h | |
| 5000h | |
| 5000h+300h |
Example B
| Scale | Audio |
|---|---|
| 300h | |
| 1500h | |
| 3000h | |
| 5000h | |
| 5000h+300h |
DSD scaling ladder
Speaker descriptionThese two DSD examples focus on whether larger training scale improves stability of persona, speaking manner, and delivery coherence.
Example A
| Scale | Audio |
|---|---|
| 300h | |
| 1500h | |
| 3000h | |
| 5000h | |
| 5000h+300h |
Example B
| Scale | Audio |
|---|---|
| 300h | |
| 1500h | |
| 3000h | |
| 5000h | |
| 5000h+300h |
RP scaling ladder
Role promptRP is where data scale and data mix are easiest to hear. These two examples make the role-intent difference across scales much more obvious.
Example A
| Scale | Audio |
|---|---|
| 300h | |
| 1500h | |
| 3000h | |
| 5000h | |
| 5000h+300h |
Example B
| Scale | Audio |
|---|---|
| 300h | |
| 1500h | |
| 3000h | |
| 5000h | |
| 5000h+300h |
Dialogue Voice Design
This is the main strength of CapTalk. The dialogue section is anchored on the final dialogue model trained on 32,171 sessions / 6270.68 hours. It starts from short full-dialogue cases, then moves through speaker consistency, objective CoT control, with-versus-without CoT comparison, and cross-system comparison.
Full multi-turn dialogue
Conversation-level demoWe present two complete dialogue sessions, not sliced utterances. In each case, the target speaker is synthesized, while the other speaker remains the original recorded voice from the session. Across these examples, the synthesized target speaker maintains stable timbre for nearly three minutes of continuous dialogue.
Case A.
性别: 男性,年龄: 青壮年,音高: 音调中心趋势偏低,基频稳定处于中低频区域,具备自然的胸腔共鸣基础,语速: 语速中心趋势偏快,节奏平稳,但在部分片段中出现快慢交替,尤其是在陈述信息时有明显的停顿与节奏调整,音量: 音量整体适中,动态范围较窄,表现出较为平稳的能量控制,清晰度: 发音清晰度良好,基本无模糊或含糊现象,流畅度: 表达流畅,偶有轻微填充词,整体无明显卡顿,口音: 带有明显南方口音,可能源自长江流域某地区,非标准普通话,音色质感: 音质干净,略带轻微的沙哑与喉音残留,发声质感偏向生活化和亲民,性格: 随和、自然,交谈风格偏向日常熟人间的轻松状态。
一个带着点南方口音的30来岁男人,声音挺稳的,不是特别亮也不算闷。说话的时候较快,有点自己的节奏,跟朋友聊家常似的,挺实在的那种。
一个老哥,在和街边小店的老板寒暄聊天,话题围绕生意和市场行情,声音里带着烟火气,也有那么一点经验丰富的老道。
Case B.
性别: 男性,年龄: 中年,音高: 音调中心趋势适中偏低,整体维持在自然男声的中低频区域,声线稳定,无剧烈波动,语速: 语速中心趋势适中,节奏平稳,但快慢切换频繁,情绪带动时语速明显加快,音量: 音量整体适中,动态范围较宽,部分片段更偏响亮,清晰度: 发音清晰度一般,偶有轻微含糊,流畅度: 整体流畅,偶有重复语句和少量填充词,口音: 普通话,带有明显的南方地域口音,影响部分字音,音色质感: 音质略显粗糙,发声不够圆润,带有轻微沙哑感,性格: 关注家庭与现实问题,情感直接,表达带有焦虑与担忧。
这是个中年的男人,声音带点南方口音,听上去挺实在的。说话时候挺关心家里的事,尤其是孩子身体和上学的事,老是提心吊胆的,时不时就唠叨两句,有点操心过头的感觉。
一位操心的儿子健康的中年父亲在向他人倾诉自己的家庭忧虑,他的语气里夹杂着对孩子成长的关心和对年迈父母的担忧,语速因情绪波动而时快时慢,声音中透露出一种真切的生活压力。
Dialogue consistency across different contexts
Speaker consistencyTwo cases are shown here. Each case keeps one target speaker fixed and compares three different dialogue contexts, making the main dialogue claim directly audible: stable target-speaker timbre across turns, while expression stays adaptive to the current local context.
Example A
| Context | Target text | Audio |
|---|---|---|
| Neutral context | 哦你上什么? | |
| Warm context | 嗯,好的,你,你你说嘛,你说呀。 | |
| Tense context | Ok不想睡睡睡不着躺躺一会儿睡,嗯。 |
Example B
| Context | Target text | Audio |
|---|---|---|
| Reassuring reply | 没事,我,最难的时候我都度过来了现在已经,风雨过了,我觉得自己想怎么做就怎么做。 | |
| Caring reply | 嗯儿子也这我儿子也这我说嘛妈妈你想去干嘛干嘛想多去玩玩。 | |
| Reflective reply | 这样子,但是他事业做的很好他就什么都很好。我在他身上学了很多东西,他是做事业型的男人我,我就在公司上班吗? |
CoT Control
Objective controllabilityThis subsection keeps only the objective controllability part and uses the final dialogue model trained on 32,171 sessions / 6270.68 hours. Same target speaker, same dialogue context, same target text, and same random seed; only one CoT attribute changes at a time. The page focuses on the three most reliable and directly audible dimensions: pitch, energy, and speed.
| Evaluation Category | Metric | Emotion | Tone | Pitch | Energy | Speed |
|---|---|---|---|---|---|---|
| CoT Prediction | Accuracy | 0.7850 | 0.7675 | 0.8375 | 0.8250 | 0.9125 |
| CoT Controllability | Success Rate | 0.7675 | 0.7675 | 0.8400 | 0.8550 | 0.8675 |
Table 3. Automatic evaluation results for dialogue voice design.
normal. Each row therefore shows the measured value and its change relative to the selected target sentence, not relative to the normal row.
Pitch
Prefer relative labels because your paper models pitch relative to each speaker's baseline.
| Value | Audio |
|---|---|
| Extremely low | |
| Noticeably low | |
| Slightly low | |
| Normal | |
| Slightly high | |
| Noticeably high | |
| Extremely high |
Energy
Again, use speaker-relative labels to match the extraction design in the paper.
| Value | Audio |
|---|---|
| Extremely quieter | |
| Noticeably quieter | |
| Slightly quieter | |
| Normal | |
| Slightly louder | |
| Noticeably louder | |
| Extremely louder |
Speed
Use speech-rate variation that is audible but not extreme enough to sound unnatural.
| Value | Audio |
|---|---|
| Extremely slower | |
| Noticeably slower | |
| Slightly slower | |
| Normal | |
| Slightly faster | |
| Noticeably faster | |
| Extremely faster |
Pitch
The labels stay speaker-relative so the comparison remains within the same dialogue identity.
| Value | Audio |
|---|---|
| Extremely low | |
| Noticeably low | |
| Slightly low | |
| Normal | |
| Slightly high | |
| Noticeably high | |
| Extremely high |
Energy
The same sentence and context are kept fixed so only loudness changes from row to row.
| Value | Audio |
|---|---|
| Extremely quieter | |
| Noticeably quieter | |
| Slightly quieter | |
| Normal | |
| Slightly louder | |
| Noticeably louder | |
| Extremely louder |
Speed
Rate changes are shown on the same target turn so the contrast stays easy to hear.
| Value | Audio |
|---|---|
| Extremely slower | |
| Noticeably slower | |
| Slightly slower | |
| Normal | |
| Slightly faster | |
| Noticeably faster | |
| Extremely faster |
Dialogue generation with and without CoT
Table 4 in audio formThis is the most important dialogue comparison on the page. Use two representative cases where the gain from CoT is easy to hear in contextual appropriateness, delivery, or role intent.
| Model Setting | Gemini | Human Pairwise Preference |
|---|---|---|
| Dialogue Eval. (w/ CoT) | 72% | 65.5% |
| Dialogue Eval. (w/o CoT) | 28% | 34.5% |
Table 4. Context coherence comparison in dialogue evaluation.
Example A
| Setting | Audio |
|---|---|
| CapTalk (w/ CoT) | |
| CapTalk (w/o CoT) |
Example B
| Setting | Audio |
|---|---|
| CapTalk (w/ CoT) | |
| CapTalk (w/o CoT) |
Cross-system dialogue comparison
Table 7 in audio formKeep this as one curated case. The target speaker in this snippet is the first speaker in the dialogue, and the key question is whether the system preserves that speaker's identity while staying coherent with the surrounding turns.
Prompt compatibility note: CapTalk uses the target-speaker natural-language caption directly. Fish Speech S2 Pro does not natively support long natural-language speaker descriptions in dialogue; it works better with short bracketed control tags. This means the Fish side is an interface-adapted comparison with matched caption meaning, but it is not a perfectly symmetric prompt setting.
| Metric | Fish Speech S2 Pro | CapTalk |
|---|---|---|
| SIM | 0.806 | 0.808 |
| Context Coherence | 3.61 | 4.18 |
| MOS | 3.80 | 4.12 |
| System | Audio |
|---|---|
| CapTalk | |
| Fish Speech S2 Pro |
Factorized Hierarchical Variational Timbre Conditioning
This section follows the paper's Section 3.3 terminology. It highlights two complementary properties of the module: stable timbre reuse once a designed voice is fixed, and one-to-many caption-conditioned sampling when the speaker embedding is re-predicted for each generation.
What this section is designed to show
As described in Section 3.3 of the paper, the hierarchical variational timbre conditioning module is inspired by the factorization idea of FHVAE. It uses an utterance-level speaker encoder and a segment-level pooled latent, with KL regularization between the segment posterior and an utterance-conditioned prior, so that stable speaker and voice attributes are preserved while segment-specific affective variation is attenuated. Its purpose is to let a designed timbre be reused across utterances and dialogue turns while keeping expression adaptive to the current context.
At the same time, caption-conditioned voice design is inherently a one-to-many task. A caption is a high-level, underspecified description that naturally corresponds to a distribution of valid voices rather than a single unique one — many concrete timbres can satisfy the same caption equally well. Furthermore, the stochastic sampling process of the model means that each generation draws a different instance from this distribution. In the standard caption-only generation setting, each run independently predicts a new êspk from the caption-conditioned distribution, so repeated samples under the same caption may sound like different but still caption-consistent voices. This sample-level variability is a property of caption-conditioned sampling, not evidence that the module fails to preserve timbre.
To directly test the timbre-reuse claim of the module, the appendix reports a dedicated timbre reuse analysis that contrasts two inference modes: Fixed êspk, where a designed voice is predicted once and then reused across utterances, and Resampled êspk, where the speaker embedding is re-predicted for every utterance. The resulting cross-utterance SIM is 0.92 in the fixed mode and 0.42 in the resampled mode, showing that once a designed voice is fixed, the module preserves it consistently across utterances.
The listening panel below is therefore meant to complement that analysis from the perceptual side: it lets listeners hear the one-to-many nature of caption-only generation directly, while the appendix numbers quantify the separate timbre-reuse path enabled by fixing the designed speaker embedding.
Each of the six cases below fixes one caption and one target text, then shows three independent generations from three separate decoding runs. These examples illustrate caption-conditioned diversity under resampled êspk, whereas the appendix timbre-reuse analysis quantifies consistency under fixed êspk.
Caption A
APS · 3 independent samples| Run | Generation |
|---|---|
| Sample 1 | |
| Sample 2 | |
| Sample 3 |
Caption B
RP · 3 independent samples| Run | Generation |
|---|---|
| Sample 1 | |
| Sample 2 | |
| Sample 3 |
Caption C
RP · 3 independent samples| Run | Generation |
|---|---|
| Sample 1 | |
| Sample 2 | |
| Sample 3 |
Caption D
DSD · 3 independent samples| Run | Generation |
|---|---|
| Sample 1 | |
| Sample 2 | |
| Sample 3 |
Caption E
APS · 3 independent samples| Run | Generation |
|---|---|
| Sample 1 | |
| Sample 2 | |
| Sample 3 |
Caption F
DSD · 3 independent samples| Run | Generation |
|---|---|
| Sample 1 | |
| Sample 2 | |
| Sample 3 |